CAPP 30122 - Computer Science with Applications 2
This course expands upon the computational thinking & skills taught in 30121, with a focus on applications to real world problems in policy-adjacent spaces. It consists of lectures, discussion sections, and programming assignments. The course culminates in a final project built on a team – expanding & demonstrating the programming & data skills built through the first two quarters.
Prerequisite: CAPP 30121 or approved equivalent course.
Quick Links
- Lecture Notes
- Ed Discussion
- Course Policies - Academic Honesty, AI, Accessibility, Code of Conduct, Diversity, Late, and Regrade policies.
- Common Grade Deductions
- Getting Help
- Using uv
- Using pytest
- CS Student Resource Guide
Course Goals
- Continue building general programming skills. Includes object-oriented programming, the structure of Python applications, and data structures.
- Learn to work with real data: including APIs and web scraping.
- Learn techniques & tools for data cleaning, merging, analysis, and visualization.
- Gain experience building a project from scratch and working on a project as part of a team.
Readings
There is no textbook, but there are supplmentary readings listed at the end of each section of the course notes.
These readings are often helpful to those that want additional depth and/or need a bit more exposure to the topic than lecture can provide.
If you ever feel like additional content on a topic would be helpful, please ask on Ed and I am glad to suggest high-quality resources.
Office Hours
| Who | Where | When |
|---|---|---|
| James Turk | JCL 398E | Monday 12-1pm |
| Raghav Mehrotra | JCL Common Area 3A | Monday 4-6pm |
| Andrés Camacho | JCL Common Area 3B | Wednesday 10am-noon |
| James Turk | JCL Common Area 3B | Wednesday 2-4pm |
| Pablo Hernandez | JCL Common Area 2B | Thursday 3-5pm |
| Maggie Larson | JCL Common Area 2A | Friday 10am-noon |
| César Núñez | JCL Common Area 3A | Friday 3-5pm |
I am also available by appointment: book a 1:1 Meeting or a group meeting.
Meeting Times
Each section will meet for lectures two days a week and with a teaching assistant for a discussion section one day a week.
| Section | Time | Location |
|---|---|---|
| #1 | Tue/Thu 9:30am-10:50am | 1155 Bldg 140C |
| #2 | Tue/Thu 11:00am-12:20pm | 1155 Bldg 140C |
| Section | Time | Location | Instructor |
|---|---|---|---|
| 1L01 | Tue 2:00-3:30pm | 1155 Building 289A | Maggie Larson |
| 1L02 | Tue 3:30-4:50pm | Rosenwald Hall 301 | Andrés Camacho |
| 2L01 | Tue 2:00-3:30pm | Crerar 011 | Raghav Mehrotra |
| 2L02 | Tue 3:30-4:50pm | Ryerson 255 | César Núñez |
Weekly Schedule
Schedule subject to change, major changes will be announced in class and on Ed Discussion.
All due dates are 11:59pm of the date listed.
Programming Labs
The 5 programming labs will be introduced in TA sessions & are meant to be worked on collaboratively. They are designed to give practice with skills that are related to upcoming PAs and/or broadly applicable for your project.
Each lab will receive a single S/N/U grade:
- S - All problems seriously attempted.
- N - Incomplete submission (requires attendance of TA session)
- U - Incomplete submission/no attendance.
These are essentially graded pass/fail, with a pass requiring a good-faith attempt at each problem.
An N is available for partial credit only if you attend the TA session. In other words: If you have a busy week & can’t find the time to finish your assignment, you can submit as far as you got during the TA session and receive an N.
Programming Assignments
The 6 programming assignments will be released in Weeks 2-6 and due in Weeks 3-7.
Assignments will typically release on Tuesday and be due the Friday of the following week.
Checking Out an Assignment
When an assignment is made available a GitHub classroom link will be posted on Ed. Clicking the link will create a new private repository for the assignment.
Once a repository is created, you will be able to clone the repository to the machine you’ll be working from.
Visit your repository on GitHub, and click on the green “Code” button. Be sure SSH is selected as pictured. Copy the URL to the repository.
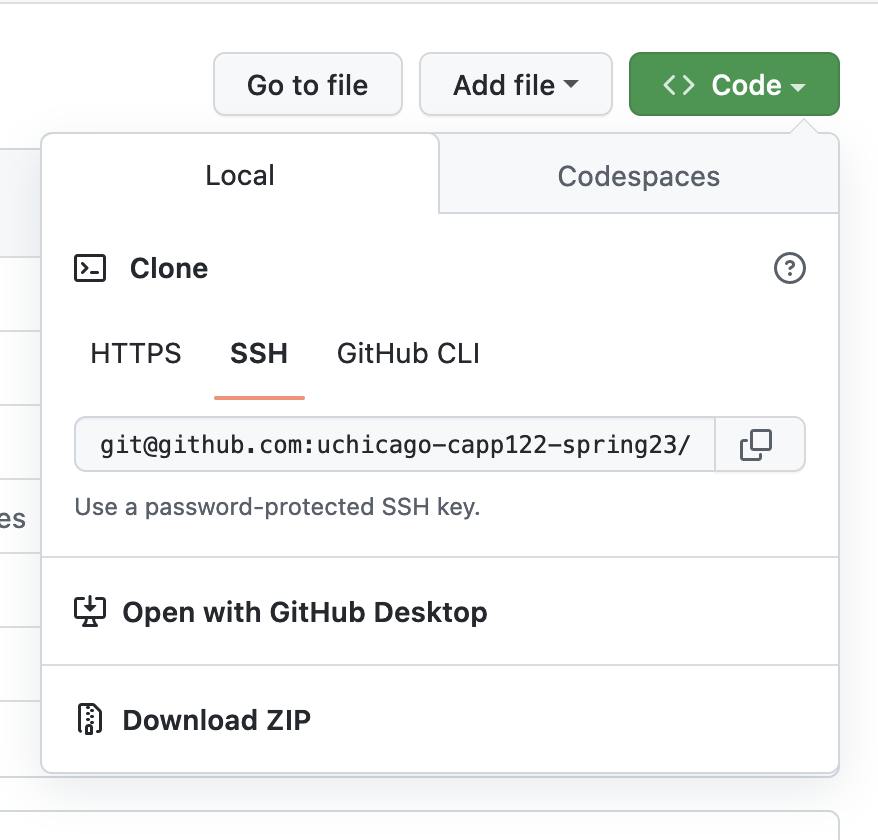
To check out your project, you can run git clone <URL> from the machine you’re doing your work on.
It is recommended you use the SSH URL option as shown above.
Tips for Working on Assignments
Work from the top-level directory. Instructions assume you are in the directory you checked out, which contains the
README.mdandpyproject.toml. While some commands may work from other directories, staying in this top-level directory will avoid lots of issues.Read the instructions carefully. The
README.mdfile contains the instructions. Make sure you understand what you’re being asked to do before you start writing code. If you’re not sure, ask for clarification on Ed.Check in often. As you work, check your code into git and push to GitHub regularly. This will help you avoid losing work if something goes wrong with your machine.
Run the tests. The tests are there to help you. If you’re not sure if your code is correct, run the tests and see if they pass as a first step. If they don’t, read the error messages carefully, they should give you a place to start investigating.
Experiment in the REPL. If you’re not sure how a particular function or method works, try it out in the REPL (
uv run python3oruv run ipython). A major advantage of interpreted languages is this ability to experiment interactively.Ask questions of course staff - If anything is not clear, ask questions via Ed! If you are stuck or need help with a concept, office hours may be a good idea as well!
Use a linter.
ruffwill be introduced in this class. Using it (or a linter of your choice) in this course will let you focus on the actual problem, help you write cleaner code, and detect common issues that may result in a lower grade.Learn
pytestshortcuts - You’ll be spending a lot of time with it, so learn how to use the command line flags. My pytest tips should be most of what you need.
Specifications Grading
We will use specifications grading for programming assignments.
See Common Deductions to get a sense of what graders will be looking for.
You will be given a set of specifications of what makes work Satisfactory, Not satisfactory, or Ungradable.
Graders will provide feedback on where your code has common issues and suggest better ways of doing things that would make your code simpler, more robust, or more efficient.
Each programming assignment will receive multiple grades based on how well it meets given specifications.
These are generally grouped into three categories:
- Completion - Generally completion will be judged based on a number of tests that need to be passed for full credit.
- Code Quality - How well the code adheres to the style guide and other quality standards outlined in the grading specification.
- Efficiency - Is the code reasonably efficient, given the general criteria observed in this class, also meeting any specific requirements made in the assignment.
For each assignment, the criteria for S & N grades will be given. For example, an assignment may state:
| Completion | Code Quality | Efficiency | |
|---|---|---|---|
| S Criteria | Pass 19/19 Tests | <=1 Deductions | <=2 Deductions |
| N Criteria | Pass 11/19 Tests | <=4 Deductions | <=5 Deductions |
Resubmissions
You will be allowed to resubmit one programming assignment.
Details on the process will be posted on Ed after the first PA.
A submission will be eligible to raise all three grades given if it fixes the mistakes of the original and incorporates grader feedback.
Course Project
In lieu of exams, this course has a quarter-long team project. During the quarter you will form a team of 3-4, identify some real-world data sets, and build a small application utilizing the data. This project will require you to apply skills you learn in class augmented with self-guided learning and exploration of your chosen data.
The project has several milestones to keep you on track, each of which will earn one grade:
- Milestone #1 - Group Formed, Proposal Due.
- Milestone #2 - Data Identified, Project Plan Revised.
- Milestone #3 - Prototype Ready, Project Check-In.
The final project requirements are numbered R1-R5, with grading criteria below.
M1: Project Proposal
The first milestone will have you provide information about the group and an initial proposal for what you plan on building.
I want your team to get a chance to build something that you are all genuinely interested in working on.
Projects should begin with two or three sources of data and a clearly stated goal.
This is just an initial proposal, details will definitely change as you work on the project throughout the quarter.
For this milestone, each team must create a group repository using the GitHub classroom link shared on Ed Discussion. (Note: Unlike regular assignments, you will be welcome & encouraged to post your projects publicly on GitHub once they are finished, so pick a name you’re happy to share with the world.)
Copy the following into a file named milestones/milestone1.md and answer the questions there:
{Replace anything in {} with your answers}
# {Team Name Here}
## Members
- {Name <name@uchicago.edu>}
- {Name <name@uchicago.edu>}
- {Name <name@uchicago.edu>}
- {Name <name@uchicago.edu>}
## Abstract
100-200 words explaining the general idea for your project. Be sure to read the project requirements below and consider how you'll incorporate the various components.
*These details can & will change as much as needed over the next few weeks.*
## Preliminary Data Sources
### Data Source #1
Source URL: {https://...}
Source Type: {Scraped/Bulk Data/API}
Summary: {What is included? who published it?}
Challenges: {Any challenges or uncertainty about the data at this point?}
### Data Source #2...N
Same as above.
## Questions
1. {Numbered list of questions for us to respond to}
2. {}Grading Specification
An S will be earned if the submission is made on time with complete answers to all questions. Late/incomplete work will earn an N for all group members.
M2: Project Plan
At this point you should have explored your data sources and spent more time revising what you plan to build based on the data and feedback.
For this milestone, answer the following in milestones/milestone2.md:
# {Team Name}
## Abstract
{Update your project abstract from Milestone 1 with any changes.}
## Data Sources
*Note that the requirements have been updated from Milestone 1!*
### Data Source #1..N
Source URL: {https://...}
Source Type: {Scraped/Bulk Data/API}
Approximate Number of Records (rows):
Approximate Number of Attributes (columns):
Current Status: {At this point, you should have interacted with your data, describe the current status. Have you written code for an API or web scraper yet, explored the data, etc.?}
Challenges: {Any challenges or uncertainty about the data at this point?}
## Data Reconciliation Plan
One of the most important steps for this milestone is to have a plan as to how your data sources will connect.
For each data set, you will need to identify the "unique key" that will allow you to connect it to other data sets.
Example 1: You have two data sets: healthcare costs on a zip code level & employment figures on a county level. You will need to determine a mapping between zip code & county. You aren't sure how you'll go about joining them-- figuring that gap out now helps us identify that this will require a third data set available from the US Census so you can plan accordingly.
Example 2: You have three data sets: a list of companies that were fined for illegal emissions, a list of companies that have government contracts, and a list of company addresses. You identify that there won't be a perfect match between the three data sets, but you will need to put some effort into matching irregularly formatted company names.
## Project Plan
The final goal of this milestone is to develop a team plan that will keep you on track for the remainder of the quarter.
1. Identify the key components of your project based on the criteria and your intended end result. (e.g. "Web scrape data source #1", "Merge code for Data Sources #2 and #3", "Map-based visualization")
2. For each component identify who will be responsible, and when it should be ready. Consider if any components rely on others and how to mitigate the effect on the dependent team members (e.g. mock data for the visualization until the real data is ready)
3. Put this together into a (rough) weekly plan. What will be built by Week 7's prototype?
## Questions
1. {A *numbered** list of questions for us to respond to.}
2. {...}Grading Specification
An S will be earned if the submission is made on time with complete answers to all questions. Late/incomplete work will earn an N for all members.
M3: Project Prototype & Check-in
At this milestone, we will take a look at what you have built so far and have a discussion about what is left to do.
Grading Specification
To earn an S your team must have:
- A repository with an appropriate project layout.
- Working data import code for at least one of your sources.
- An initial draft of data reconciliation/cleaning process.
- An initial draft of the final visualization/simulation/etc. that may be using mock data at this point.
- The beginning of a README.
- Finally, the team will attend a meeting with course staff to discuss the state of the project.
This milestone is primarily to help us help you. The more code you have written the better our discussion can be, and that will lead to a stronger project.
An N may be given if any of the above criteria are not met.
A U may be given if two or more are not met.
If a team member has not made any code contribution by this point, or fails to attend the team meeting, their grade may be lower than the grade earned by the group.
R1: Core Requirements Met
To earn an S on this portion, the project must meet all of the core requirements:
- At least two distinct sources of data. At least one of which is an API or scraped from a website.
- A data reconciliation component. Data from two or more data sets should be joined using data that they have in common such as names or zip codes.
- A data analysis component. Data could be used for a simulation, prediction, or statistical analysis. This criteria is quite flexible, but work with course staff to make sure that it is scoped appropriately.
- A visual output. This may be text or graphical, but a user should be able to interact with your program and the results of the analysis component.
- Specific components built by each team member. Every team member must be responsible for implementing a component of the project’s software. For example: two team members might each handle scraping separate data sources, a third member might write the core of the simulation, and the fourth member the visuals. Lines of code are a deeply flawed metric, but around 200 lines of code per person is an approximate minimum. (This is not an exact rule, 90 lines of well-written, complex Python might be significantly more work than a 400-line contribution that is fairly repetitive.)
R2: Efficiency & Correctness
In addition to meeting the core requirements, we will evaluate if your project is reasonably efficient, correctly applying concepts learned in class.
Given the nature of the projects it is not possible to provide a comprehensive rubric, but deductions here would come from:
- Significantly inefficient/incorrect code. - Code that is either significantly less efficient or that contains an unusually high number of issues.
- Mishandling data. - Does your code combine incompatible data or make other mistakes that jeopardize the validity of your analysis?
- Misleading representations of data. - A final product with flaws that would lead to an audience drawing incorrect conclusions.
R3: Testing
Your code should include tests for a few key pieces of functionality.
The testing does not need to be comprehensive, but should test key points that should inspire confidence that your code works as intended.
While every project is different, a rough idea of what you might test:
- A couple of tests per data source, for example:
- Test that your API or web scraping code correctly fetches the data from a single page.
- Test the conversion of a single record from the upstream into your internal cleaned-up representation.
- Thoughtful tests of your data reconciliation code on a small subset of your data (real or mocked).
- Testing of analysis component.
Each of these components should have 2-3 tests, aiming to cover critical cases.
An S will be given if most of these exist, allowing some room for 1-2 cases that are difficult to test to be omitted.
An N will be given if a critical component is omitted or a substantial number of smaller components are not tested.
A U would be considered if few to no tests are provided.
R4: Code Quality
To earn an S the project will be expected to adhere to all code quality guidelines in place throughout the course.
Additional requirements will be added here and announced well in advance in class and on Ed:
- Repository structure - Is the project a complete Python project structured as shown in class in a well-organized and cohesive way.
- All code executable from command line - Code that is important to the project should have a clearly documented command that we can run. It is acceptable to have multiple steps (e.g.
uv run python -m myapp.downloadfollowed byuv run python -m myapp.clean), but it is not acceptable to use Jupyter notebooks or other tools that do not allow this style of execution.
R5: Documentation
To earn an S for this portion, your project will need two additional files and a short demo video.
README.md
The README.md serves as a public-facing landing page for the project. It should contain:
- the project name & updated final abstract
- names of each team members
- a screenshot of your project
- instructions on how to run the project (1-3 commands)
- citations for your data sources
- a link to your project video
Final Milestone
Within the milestones/ directory. Add a project named final.md or final.pdf. This is the “internal” documentation for your project.
This document should be 2-3 pages. Please do not go longer than that.
- Data Documentation - List the sources of data, any gaps or challenges in the data. Explain how data flows through the project. What else would someone picking this project up for the first time need to understand?
- Project Structure - Write a page or so describing the structure of your project. What modules exist? What do they do? A diagram may be helpful here.
- Team responsibilities - Give a detailed breakdown of who built what. Remember, each team member needs a significant contribution.
- Final thoughts - Reflect on what the project intended to accomplish and what it did.
Demo Video
Record a video demonstrating your project. The video must be between 1 and 5 minutes.
You may upload this video to YouTube or another hosting service, or to a file sharing service (Box, Google Drive, etc.) and send me a link.
Individual Grade Adjustment
Individual grades may be adjusted if the team evaluation or observation of the code itself reveals significant shortcomings or differences in contribution between team members.
Project Fair & Final Submission
Monday of Week 10 (Finals Week) we will have a project fair. This is a chance to show off what you made and celebrate what you all built.
Attendance at the project fair is required as it is scheduled in lieu of a final. Failure to attend will result in an individual grade adjustment for two of the final criteria.
I strongly recommend your team sets an internal deadline to have things combined/merged ~24 hours prior to the event. Give yourself a buffer, you do not want to be making big last-minute changes the day you are planning to demo things.
After this deadline, you have an additional day or so to make final cleanups to your code. It is recommended that you use this time for documentation, final clean-up, and minor changes.
All final project commits must be made by Tuesday 11:59pm of Week 10.
We will not grade anything committed to the repository after this deadline.
Grading
Final Grade Calculation
| Type | Number | Points (each) | Total Points |
|---|---|---|---|
| Programming Assignment | 6 | 3 | 18 |
| Lab | 5 | 1 | 5 |
| Project Milestones | 3 | 1 | 3 |
| Project Final | 5 | 1 | 5 |
| Bonus | 2 | 1 | 2 |
This is a total of 33 points.
(The two bonus assignments will be introduced during the quarter.)
Each row has a minimum number of S grades, as well as a maximum number of U grades. N grades are not shown, but are significant to your grade in that partial credit is far less damaging to your prospects than missing work.
| Letter Grade | S >= | U <= |
|---|---|---|
| A | 31 | 0 |
| A- | 29 | 2 |
| B+ | 27 | 3 |
| B | 25 | 4 |
| B- | 23 | 5 |
| C+ | 21 | 6 |
| C | 19 | 7 |
| C- | 16 | 9 |
Academic Honesty violations, including use of AI, will earn all U on affected assignments. You will not be allowed to replace these grades with a resubmission, and the highest grade you will be eligible to earn wiil be capped at a B.
This is, without a doubt, the most common way to get a low grade or fail this course. Do not share your work, ask others to, or use generative AI on assignments in any way.
C- is the minimum grade to receive credit for this course.
The scale is designed to be forgiving of an assignment or two going poorly, or skipping 1-2 labs or the bonus assignments.
For example, someone with 2N and 2 missing small assignments can earn an A-.
From there, the scale continues to be forgiving of the occasional N, but less so of missing work. 3U will cap your maximum grade at a B+, and 6 at a C+.
The lesson here should be to turn in your best work for every assignment when it is due. That, combined with following style guidelines and other criteria will keep you out of jeopardy.
If you feel that you are at risk of falling behind reach out to James proactively to discuss options.
I reserve the right to adjust the table at the end of the quarter, but would only do so to adjust the course curve in everyone’s favor (e.g. if there is a significant issue with an assignment)