14 Extending Python
When is Python not enough?
- When we need the raw memory access/speed that only lower-level languages can provide.
- When we need to circumvent the GIL (releasing GIL is only possible in C code).
- When binding to a third-party library written in another language.
Clarification: CPython
We will often use the term CPython.
This is the default implementation of Python. Written in C, downloaded from python.org.
(Not to be confused with Cython, which we’ll see a bit later.)
The Search for a Faster Python
Python’s speed started to become a concern about 20 years ago (10 years after it was created), as larger projects like Instagram and YouTube began to use Python for things that it was not originally imagined for.
Option 1. Parallelization/Vectorization
multiprocessing- sidestep GIL using processes (2008, Python 2.6)- NumPy vectorization - offloads loops to C/BLAS (2006, preceeded by Numeric in 1995)
concurrent.futures- 2010 Python 3.2
Option 2. Make CPython Faster
- Unladen Swallow — Google-funded JIT attempt, abandoned (2009–2011)
- PEP 659 specializing adaptive interpreter — “CPython goes faster” merged (2021, Python 3.11)
- Free-threaded CPython / no-GIL — PEP 703, experimental in 3.13 (2023–present)
Option 3. A New Interpreter
- Jython: CPython in Java, JVM JIT for free (1997)
- IronPython: CPython on .NET CLR (2006)
- PyPy: RPython-based JIT, often 5–10× faster (2007-)
- Pyston: Dropbox-funded JIT, abandoned (2014-2019)
- Cinder: Instagram’s CPython fork with JIT (2021-?)
Lots of companies (Microsoft, Dropbox, Meta) have put money into this idea. In practice it rarely gets traction.
Problems:
- Lags CPython, which moves at a steady pace.
- While Python is fairly well-defined, any deviation from CPython likely to introduce bugs. (
ctypes/PyPy issues)
Only real exception is PyPy, but latest PyPy release only supports 3.11. Development slowed drastically as CPython got faster.
My guess: JIT/Free Threading/etc. will be too complex for implementations to keep up with. Extension support already a major problem for adoption. Projects will become elss relevant.
I would watch for a Rust-based implementation of Python, someone will try it– the question is will CPython adopt enough Rust first to make that unnecessary.
Option 4. Extend in C / Make Python Easier to Extend
- C API: built in from the start, lowest-level access to Python internals (1991)
- SWIG: auto-generate C/C++ bindings (1995)
boost.python: C++ specific helpers (2002)ctypes: Call C from Python without complilation step (2003, Python 2.6)- Cython: Python-like language that compiles to C (2007)
cffi: C Foreign Function Interface, call C code from Python (works with PyPy) (2012)- PyO3: Rust bindings, becoming the default for new extension (2017)
All-of-the-above
Python has seen major overhauls to the interpreter: a new parser, an experimental JIT (PEP 744), experimental free-threading/no-GIL (next week’s topic).
At the same time, the C API will always be maintained, and PyO3 is becoming the default for most extension authors. Experimental PEPs suggest that Rust will soon be allowed in the CPython core, which most likely means a stable interface.
Extending Python Case Study: jellyfish
jellyfish is a library that contains fuzzy string comparison functions.
It was written by a colleague of mine and me–and has become one of the open source libraries I’ve written that has the most users.
Most of these algorithms take two strings and return a score, the various algorithms range in complexity from \(O(n)\) to \(O(n^3)\) on the length of the string.
Furthermore, these algorithms are typically used in large record-linkage problems. Let’s say we have datasetA, 100,000 business names; datasetB 250,000 legal records, and the average length of a string is 15 characters. These are realistic numbers, and far from the largest possible cases.
Comparing each item from A to B would be 25 billion AxB comparisons. Comparing 25 billion 15-character strings in Python takes about 150 seconds on my laptop. (2-3 minutes)
String comparison is \(O(N)\). The time complexity of an algorithm like Damerau-Levenshtein which counts the number of string edits is \(O(N^3)\). For 15-character strings this means it will take at least 225-times longer (15**2).
Our four minute run is now potentially 11 hours. And that’s an optimistic scenario. In reality, the algorithm in Python will be doing a lot more work than the C-optimized str == str.
In practice, we can try this with jellyfish’s Python implementation:
timeit.timeit("jellyfish._jellyfish.damerau_levenshtein_distance('abcdefghijklmnop', 'abcdefghijklmn0q')')", number=1_000_000) * 2500 / 60 / 6025.51281035
This suggests a full run would take ~25 hours.
Fortunately, jellyfish has a Rust implementation as well, using that instead:
timeit.timeit("jellyfish.damerau_levenshtein_distance('abcdefghijklmnop', 'abcdefghijklmn0q')')", number=1_000_000) * 2500 / 60 / 602.15540
A 10x speedup! An algorithm that takes 25 hours to run may not be practical, and when something goes wrong you find out more than a day later. 2 hours is much more managable for work like this.
| Operation | Time to run on AxB (25 billion) |
|---|---|
str.__eq__ |
3 minutes |
| Damerau (Python) | 25 hours |
| Damerau (Rust) | 2 hours |
Let’s look at the real implmenetations of the Python, Rust, and old C versions of a related (but slightly simpler) function: levenshtein_distance.
Python
def levenshtein_distance(s1, s2):
_check_type(s1)
_check_type(s2)
if s1 == s2:
return 0
rows = len(s1) + 1
cols = len(s2) + 1
if not s1:
return cols - 1
if not s2:
return rows - 1
prev = None
cur = range(cols)
for r in range(1, rows):
prev, cur = cur, [r] + [0] * (cols - 1)
for c in range(1, cols):
deletion = prev[c] + 1
insertion = cur[c - 1] + 1
edit = prev[c - 1] + (0 if s1[r - 1] == s2[c - 1] else 1)
cur[c] = min(edit, deletion, insertion)
return cur[-1]Rust
pub fn vec_levenshtein_distance<T: PartialEq>(v1: &FastVec<T>, v2: &FastVec<T>) -> usize {
let rows = v1.len() + 1;
let cols = v2.len() + 1;
if rows == 1 {
return cols - 1;
} else if cols == 1 {
return rows - 1;
}
let mut cur = range_vec(cols);
for r in 1..rows {
// make a copy of the previous row so we can edit cur
let prev = cur.clone();
cur = smallvec![0; cols];
cur[0] = r;
for c in 1..cols {
// deletion cost or insertion cost
let del_or_ins = cmp::min(prev[c] + 1, cur[c - 1] + 1);
let edit = prev[c - 1] + (if v1[r - 1] == v2[c - 1] { 0 } else { 1 });
cur[c] = cmp::min(del_or_ins, edit);
}
}
// last element of bottom row
cur[cols - 1]
}
pub fn levenshtein_distance(s1: &str, s2: &str) -> usize {
if s1 == s2 {
return 0;
}
let us1 = UnicodeSegmentation::graphemes(s1, true).collect::<FastVec<&str>>();
let us2 = UnicodeSegmentation::graphemes(s2, true).collect::<FastVec<&str>>();
vec_levenshtein_distance(&us1, &us2)
}
// And this final function exposed the Python interface.
// It is a thin wrapper around the Rust version.
// (Some libraries would just combine these,
// but it was a design goal to leave the functions callable
// from pure-Rust as well as Python)
// Calculates the Levenshtein distance between two strings.
#[pyfunction]
fn levenshtein_distance(a: &str, b: &str) -> PyResult<usize> {
Ok(_lev(a, b))
}C
int levenshtein_distance(const JFISH_UNICODE *s1, int s1_len, const JFISH_UNICODE *s2, int s2_len)
{
size_t rows = s1_len + 1;
size_t cols = s2_len + 1;
size_t i, j;
unsigned result;
unsigned d1, d2, d3;
unsigned *dist = safe_matrix_malloc(rows, cols, sizeof(unsigned));
if (!dist) {
return -1;
}
for (i = 0; i < rows; i++) {
dist[i * cols] = i;
}
for (j = 0; j < cols; j++) {
dist[j] = j;
}
for (j = 1; j < cols; j++) {
for (i = 1; i < rows; i++) {
if (s1[i - 1] == s2[j - 1]) {
dist[(i * cols) + j] = dist[((i - 1) * cols) + (j - 1)];
} else {
d1 = dist[((i - 1) * cols) + j] + 1;
d2 = dist[(i * cols) + (j - 1)] + 1;
d3 = dist[((i - 1) * cols) + (j - 1)] + 1;
dist[(i * cols) + j] = MIN(d1, MIN(d2, d3));
}
}
}
result = dist[(cols * rows) - 1];
free(dist);
return result;
}And like Rust, we need to wrap in Python objects:
static PyObject* jellyfish_levenshtein_distance(PyObject *self, PyObject *args)
{
PyObject *u1, *u2;
Py_UCS4 *s1, *s2;
Py_ssize_t len1, len2;
int result;
if (!PyArg_ParseTuple(args, "UU", &u1, &u2)) {
PyErr_SetString(PyExc_TypeError, NO_BYTES_ERR_STR);
return NULL;
}
len1 = PyUnicode_GET_LENGTH(u1);
len2 = PyUnicode_GET_LENGTH(u2);
s1 = PyUnicode_AsUCS4Copy(u1);
if (s1 == NULL) {
return NULL;
}
s2 = PyUnicode_AsUCS4Copy(u2);
if (s2 == NULL) {
PyMem_Free(s1);
return NULL;
}
result = levenshtein_distance(s1, len1, s2, len2);
PyMem_Free(s1);
PyMem_Free(s2);
if (result == -1) {
// levenshtein_distance only returns failure code (-1) on
// failed malloc
PyErr_NoMemory();
return NULL;
}
return Py_BuildValue("i", result);
}This uses the Python C API: https://docs.python.org/3/extending/extending.html
The full libraries are all available at https://codeberg.org/jpt/jellyfish and https://codeberg.org/jpt/cjellyfish.
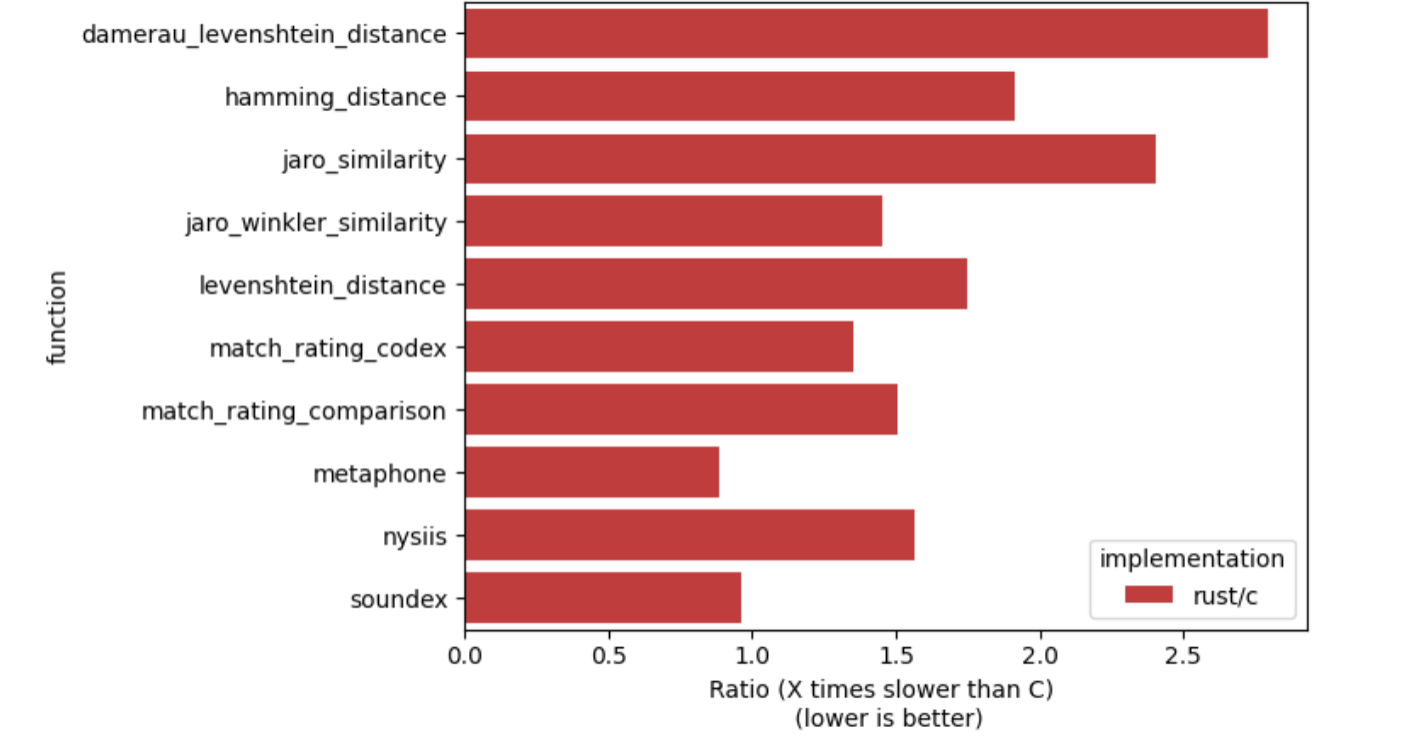
Perfomance Outcome
Time Comparison of All Algorithms
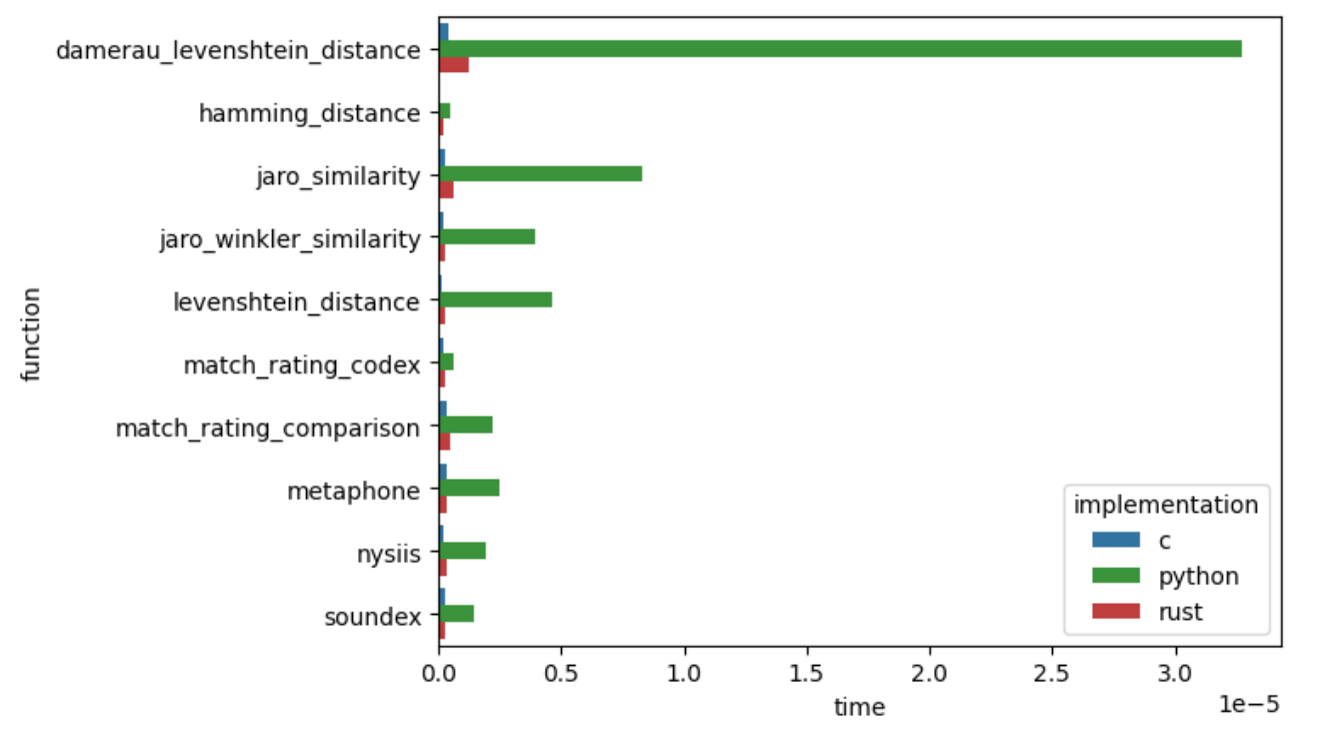
Time Comparison of All Algorithms (normalized to compare to C)
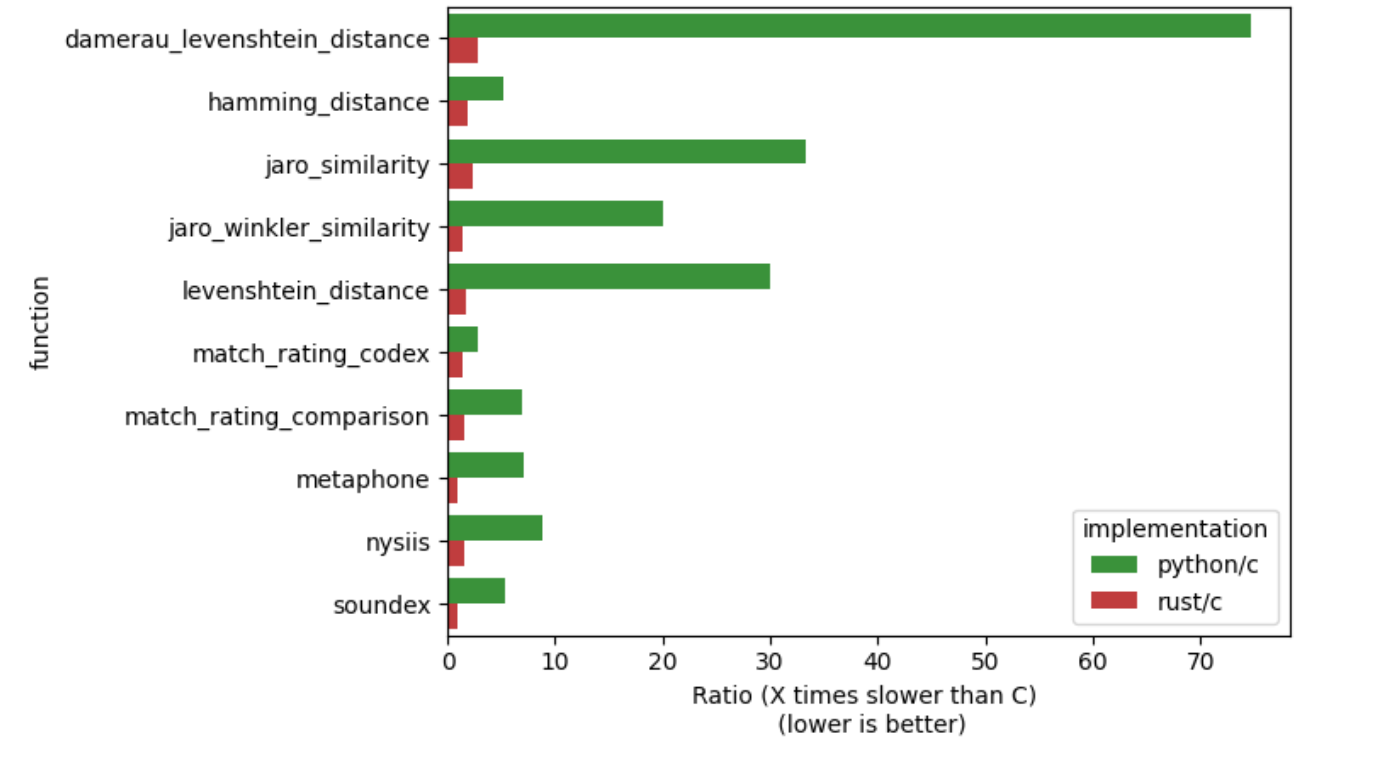
Rust vs. C Time Comparisons
Extending Python
Now that we’ve seen an example, let’s take a look at what it actually takes to extend Python with other languages.
These other languages are compiled, this means there’ll be an additional build step where our C/Rust/etc. code gets compiled and turned into a shared object file, something that Python can import.
C API
Python’s C API is a series of C functions and objects that are used under the hood to write Python itself.
Every Python object is a PyObject*, a structure in memory which represents the kind of object, the value, and the reference count.
Since Python is a garbage-collected language, and C is not, the reference count must be manually incremented and decremented when you are using an object and done with it. (Py_INCREF / Py_DECREF)
C code is much more difficult to make platform agnostic, but the Python C API does have some functions to help with this.
Let’s take a second look at levenshtein, this time with annotations:
// Return type and arguments are all PyObject*
// `self` here is the module (not used directly)
// `args` is a tuple which we'll parse into two strings
static PyObject* jellyfish_levenshtein_distance(PyObject *self, PyObject *args)
{
// we create two unicode-strings u1 and u2
PyObject *u1, *u2;
// we need to know/care about the internal implementation of
// unicode, here UCS4
Py_UCS4 *s1, *s2;
// these are integers
Py_ssize_t len1, len2;
// a C int that will store the result
int result;
// extract two unicode args from the argument list, or TypeError
if (!PyArg_ParseTuple(args, "UU", &u1, &u2)) {
PyErr_SetString(PyExc_TypeError, NO_BYTES_ERR_STR);
return NULL;
}
// C version of `len1 = len(u1)`
len1 = PyUnicode_GET_LENGTH(u1);
len2 = PyUnicode_GET_LENGTH(u2);
// we copy the unicode data into a C string
s1 = PyUnicode_AsUCS4Copy(u1);
if (s1 == NULL) {
return NULL;
}
s2 = PyUnicode_AsUCS4Copy(u2);
if (s2 == NULL) {
// if this UCS4 conversion fails, we free the memory
// allocated to s1
// keeping track of these things is important to avoid
// C extensions which leak memory
PyMem_Free(s1);
return NULL;
}
// here we call our actual C implementation of the function
// which doesn't know about Python (a good idea to keep the)
// Python specific parts in a wrapper function like we do here
result = levenshtein_distance(s1, len1, s2, len2);
// we are now done with both s1 and s2 (C string version of our string)
PyMem_Free(s1);
PyMem_Free(s2);
if (result == -1) {
// levenshtein_distance only returns failure code (-1) on
// failed malloc
PyErr_NoMemory();
return NULL;
}
// we convert our C int back into a PyObject
return Py_BuildValue("i", result);
}We then need to take this function and wrap it in a module:
static PyMethodDef jellyfish_methods[] = {
// truncated ...
{"levenshtein_distance", jellyfish_levenshtein_distance, METH_VARARGS,
"levenshtein_distance(string1, string2)\n\n"
"Compute the Levenshtein distance between string1 and string2."},
// truncated ...
{NULL, NULL, 0, NULL}
};
static struct PyModuleDef moduledef = {
PyModuleDef_HEAD_INIT,
"jellyfish.cjellyfish",
NULL,
sizeof(struct jellyfish_state),
jellyfish_methods,
NULL,
NULL,
NULL,
NULL
};
PyObject* PyInit_cjellyfish(void)
{
PyObject *unicodedata;
PyObject *module = PyModule_Create(&moduledef);
if (module == NULL) {
INITERROR;
}
unicodedata = PyImport_ImportModule("unicodedata");
if (!unicodedata) {
INITERROR;
}
GETSTATE(module)->unicodedata_normalize =
PyObject_GetAttrString(unicodedata, "normalize");
Py_DECREF(unicodedata);
return module;
}ctypes/cffi
These provide an alternate approach to linking in C code. Instead of writing our own PyObject*/INCREF/DECREF style C code, we take the pure-C implementation and build it into a C library suitable to be called from Python or any language.
Then with ctypes:
import ctypes
jf = ctypes.CDLL("./jellyfish.so")
jf.jaro_winkler("hello world", "h3ll0 w0r1d")Or with cffi:
from cffi import FFI
ffi = FFI()
ffi.cdef("int jaro_winkler(const char* a, const char* b);")
jf = ffi.dlopen("./jellyfish.so")
jf.jaro_winkler("hello world", "h3ll0 w0r1d")There is a bit of overhead here, but is an option for wrapping existing C libraries or avoiding the complexity of building a custom C extension.
Rust / PyO3
Rust is a low-level systems language focused on memory safety. It aims to make it impossible to write code that leaks memory, contains buffer overruns, and other common security and reliability problems endemic to C code.
Compiled Rust code is competitive with C in terms of speed and memory usage.
The language itself has many powerful features, among them Rust macros– a form of metaprogramming. Rust macros allow libraries to provide code that rewrites Rust code, and this power is utilized in the popular PyO3 library which allows automatically translating Rust code to the C-API equivalent. We can see this in the Jellyfish example above:
pub fn vec_levenshtein_distance<T: PartialEq>(v1: &FastVec<T>, v2: &FastVec<T>) -> usize {
// pure rust implmeentation (template version)
}
pub fn levenshtein_distance(s1: &str, s2: &str) -> usize {
// pure rust implementation with unicode specialization
}
// The only rust specific code is a wrapper function that is annotated with
// the pyfunction macro and a function that initializes the module:
#[pyfunction]
fn levenshtein_distance(a: &str, b: &str) -> PyResult<usize> {
Ok(_lev(a, b))
}
#[pymodule]
pub fn _rustyfish(_py: Python, m: &Bound<'_, PyModule>) -> PyResult<()> {
m.add_function(wrap_pyfunction!(levenshtein_distance, m)?)?;
m.add_function(wrap_pyfunction!(soundex, m)?)?;
m.add_function(wrap_pyfunction!(metaphone, m)?)?;
// truncated ...
Ok(())
}For more details see the PyO3 bindings: https://pyo3.rs and https://www.maturin.rs
It is easy to see why more and more Python extensions are being written in Rust:
- No manual reference counting, automatic conversion to PyObject types.
- Rust’s type system catches entire classes of bugs at compile time.
maturinhandles all the build/packaging complexity- Almost the same performance as C.
- Access to Rust library ecosystem.
Cython
Cython, not to be confused with CPython, is a language that is a cross between Python and C, meant to compile to C and be callable from Python.
https://docs.cython.org/en/latest/
For a long time it was the easiest-to-package, but PyO3/maturin may now hold that title. The advantage it still holds is that only minimal modifications are needed. Existing Python code can be translated to cython with a few changes: declaring variables, annotating functions (in a Cython specific way) and placing these in .pyx files:
# levenshtein.pyx
def levenshtein(str s1, str s2) -> int:
cdef int len1 = len(s1)
cdef int len2 = len(s2)
cdef int i, j
cdef list row = list(range(len2 + 1))
for i in range(1, len1 + 1):
prev = row[:]
row[0] = i
for j in range(1, len2 + 1):
row[j] = min(
prev[j] + 1,
row[j - 1] + 1,
prev[j - 1] + (0 if s1[i - 1] == s2[j - 1] else 1)
)
return row[len2]This is then built with a custom setup.py for the library:
from setuptools import setup
from Cython.Build import cythonize
setup(ext_modules=cythonize("levenshtein.pyx"))python setup.py build_ext --inplaceThe speedups here are slower than C, but often signficant. The overhead in the generated code is minimal and can allow doing C-like things without learning a whole new language.
Conclusion
| Cython | C API | Rust/PyO3 | |
|---|---|---|---|
| Learning curve | Low | High | Medium |
| Safety | Medium | Low | High |
| Performance | High | Highest | High |
| Packaging | OK | Hard | OK |
| Best for | Augmenting existing Python | C bindings/Tight CPython integration | New extensions |
Additional Starter Template Examples
Since actually getting the module to build can be the hard part for new extension authors, it can also be helpful to see a minimal working example of an extension:
C
hello.c
pyproject.tomlhello.c
#define PY_SSIZE_T_CLEAN
#include <Python.h>
static PyObject* hello(PyObject* self, PyObject* args) {
return PyUnicode_FromString("hello from C");
}
static PyMethodDef methods[] = {
{"hello", hello, METH_NOARGS, NULL},
{NULL, NULL, 0, NULL}
};
static struct PyModuleDef module = {
PyModuleDef_HEAD_INIT, "hello", NULL, -1, methods
};
PyMODINIT_FUNC PyInit_hello(void) {
return PyModule_Create(&module);
}[project]
name = "hello"
version = "0.1"
[build-system]
requires = ["setuptools"]
build-backend = "setuptools.build_meta"
[tool.setuptools]
ext-modules = [{name = "hello", sources = ["hello.c"]}]Then run:
# builds the C extension
uv build
# you can now use the module like any other
uv run python -c "import hello; print(hello.hello())"Minimal Rust Example with PyO3 and Maturin
Setup
uv add maturin
uv run maturin init --bindings pyo3 # scaffolds a Rust projectThis will create the required layout for you, then you can modify src/lib.rs
use pyo3::prelude::*;
#[pyfunction]
fn hello() -> &'static str {
"hello from Rust"
}
#[pymodule]
fn hello_ext(m: &Bound<'_, PyModule>) -> PyResult<()> {
m.add_function(wrap_pyfunction!(hello, m)?)?;
Ok(())
}# builds the Rust extension
uv run maturin develop
# you can now use the module like any other
uv run python -c "import hello_ext; print(hello_ext.hello())"